这篇文章的主题是在完成安全通论第一次作业的过程中想到的,虽然现在回过头来看感觉还是有点幽默。下面是作业题目原内容:
来源 :安全通论作业一:数值分析攻击信道容量内容 :用matlab/python等作图工具,数值分析攻击信道容量。要求 :形成分析报告,字数不限。以PDF附件形式上传~
本来说是不用算的,然后作业里面我就把攻击信道容量算出来了(见附录),而且从其图像来看确实在那个模型下不安全的情况一定存在(攻击信道容量 > 0)。。。但是解释起来着实有点牵强,最后的理解还是攻击方能够产生的最大威胁当量 。不过这个作业也算给了我一些比较好的启发,尝试基于学过的一些理论的内容,构建模型。虽然说是人家好像在十几年前就利用乔姆斯基范式研究过了(LangSec),而且还证明了一定不存在完全安全的软件。哈哈哈。但是过程挺好玩的,遂分享。 问题也挺多的,比如把系统抽象为 DFA 是否合理,资源函数也是存在一定定义问题。。然后把防御方也分开成了一个 PPT,攻击方也进行了分级别的抽象等等。还有灰盒模型的建模,求出来的界好像也有点怪怪的。 娱乐性质大于科学性。√
1. 基本建模
1.1 攻防双方的形式化建模
对于攻防双方,我们将其各自抽象为一个概率多项式图灵机:
【防守方】 考虑非动态变化的防守方,即防守方提前部署策略,它不知道哪个攻击方会进行什么攻击,它的机器为多项式时间图灵机 :
M D ( x ) → { 0 , 1 } \mathcal{M}_D(x) \to \{0, 1\}
M D ( x ) → { 0 , 1 }
其中 1 1 1 0 0 0
设 M D \mathcal{M}_D M D
L D = M D − 1 ( 1 ) L_D = \mathcal{M}_D^{-1}(1)
L D = M D − 1 ( 1 )
同时定义防守资源函数 :
ψ ( L D ) = min M : L ( M ) = L D { max x ∈ Σ ∗ { T M ( x ) + S M ( x ) } } \psi(L_D) = \min_{M:L(M)=L_D} \left\{ \max_{x\in\Sigma^*} \left\{ T_M(x) + S_M(x) \right\} \right\}
ψ ( L D ) = M : L ( M ) = L D min { x ∈ Σ ∗ max { T M ( x ) + S M ( x ) } }
这里我们考虑 max \max max 算法复杂度攻击 的攻击方式。例如,防守方使用正则表达式引擎(一种判定图灵机)来匹配恶意特征。大部分正常的载荷在几毫秒内就能匹配完成,但攻击者可以精心构造一个引发 ReDoS 的特定载荷 x w o r s t x_{worst} x w o r s t x w o r s t x_{worst} x w o r s t T M ( x w o r s t ) + S M ( x w o r s t ) T_M(x_{worst}) + S_M(x_{worst}) T M ( x w o r s t ) + S M ( x w o r s t )
形式上定义防守方可以承载的资源最大值 为 R D \mathcal{R}_D R D
ψ ( L D ) ⩽ R D \psi(L_D) \leqslant \mathcal{R}_D
ψ ( L D ) ⩽ R D
【攻击方】 攻击方定义为两个阶段的图灵机 M A \mathcal{M}_A M A
输入:环境资源描述 ⟨ S ⟩ , 随机数 r 运行: 1. w ∗ ← M A off ( ⟨ S ⟩ , r ) ; 2. x ← M A on ( ⟨ S ⟩ , w ∗ , r ) ; 输出: x \begin{aligned}
&\text{输入:环境资源描述 }\langle S \rangle, \text{随机数} r\\
&\text{运行:}\\
&\qquad 1.\quad w^*\leftarrow \mathcal{M}_A^{\text{off}}(\langle S \rangle, r);\\
&\qquad 2.\quad x\leftarrow \mathcal{M}_A^{\text{on}}(\langle S \rangle, w^*, r);\\
&\text{输出:}x
\end{aligned}
输入:环境资源描述 ⟨ S ⟩ , 随机数 r 运行: 1 . w ∗ ← M A off ( ⟨ S ⟩ , r ) ; 2 . x ← M A on ( ⟨ S ⟩ , w ∗ , r ) ; 输出: x
其中 ⟨ S ⟩ \langle S\rangle ⟨ S ⟩ r r r w w w 凸显出攻击方的核心资产:漏洞证据 。
若 w = ∅ w = \emptyset w = ∅ 什么都不知道 的状态,它是盲打击的;
若 w = w CVE w = w_{\text{CVE}} w = w CVE 漏洞处于 1-day 状态 ,攻防双方需要比拼谁先利用漏洞或者打上补丁;
若 w = w 0-day w = w_{\text{0-day}} w = w 0-day
同样定义攻击资源函数 :
Φ ( M A ) = max x ∈ Σ ∗ { T M A off ( x ) + S M A off ( x ) } + max x ∈ Σ ∗ { T M A on ( x ) + S M A on ( x ) } \Phi(\mathcal{M}_A) = \max_{x\in \Sigma^*} \left\{ T_{\mathcal{M}_A^{\text{off}}}(x) + S_{\mathcal{M}_A^{\text{off}}}(x) \right\} + \max_{x\in \Sigma^*} \left\{ T_{\mathcal{M}_A^{\text{on}}}(x) + S_{\mathcal{M}_A^{\text{on}}}(x) \right\}
Φ ( M A ) = x ∈ Σ ∗ max { T M A off ( x ) + S M A off ( x ) } + x ∈ Σ ∗ max { T M A on ( x ) + S M A on ( x ) }
类似地,形式上定义攻击方可以承载的资源最大值 为 R A \mathcal{R}_A R A
Φ ( M A ) ⩽ R A \Phi(\mathcal{M}_A) \leqslant \mathcal{R}_A
Φ ( M A ) ⩽ R A
记黑客生成的载荷子集为:
Supp ( M A ) = { x ∈ Σ ∗ ∣ Pr ( M A → x ) > 0 } \text{Supp}(\mathcal{M}_A) = \left\{ x \in \Sigma^* \mid \Pr(\mathcal{M}_A \to x) > 0 \right\}
Supp ( M A ) = { x ∈ Σ ∗ ∣ Pr ( M A → x ) > 0 }
我们还需要对防守方的业务相关内容进行建模。
根据防守方的 PPT 机器 M A \mathcal{M}_A M A 状态集合 为 S \mathbb{S} S
S S ⊆ S \mathcal{S}_S \subseteq \mathbb{S} S S ⊆ S S U = S − S S \mathcal{S}_U = \mathbb{S} - \mathcal{S}_S S U = S − S S
在单论攻防交互下,考虑防守方的业务 是一个概率状态转移的过程,即概率状态转移函数 δ \delta δ
δ : S × Σ ∗ × S → [ 0 , 1 ] \delta : \mathbb{S} \times \Sigma^* \times \mathbb{S} \to [0, 1]
δ : S × Σ ∗ × S → [ 0 , 1 ]
此时应当有要求,对于任意给定的当前状态 s s s x x x s ′ s' s ′
∑ s ′ ∈ S δ ( s , x , s ′ ) = 1 \sum_{s'\in \mathbb{S}} \delta(s, x, s') = 1
s ′ ∈ S ∑ δ ( s , x , s ′ ) = 1
单个字符的转移函数记为 δ 0 : S × Σ × S → [ 0 , 1 ] \delta_0: \mathbb{S} \times \Sigma \times \mathbb{S} \to [0, 1] δ 0 : S × Σ × S → [ 0 , 1 ]
对于单论攻防,设系统处于某个初始状态 s 0 s_0 s 0 x x x
p u ( s 0 , x ) = Pr x ∈ Σ ∗ ( from s 0 to unsafe ) = ∑ s ′ ∈ S U δ ( s 0 , x , s ′ ) p_u(s_0, x) = \Pr_{x\in\Sigma^*} (\text{from } s_0 \text{ to unsafe}) = \sum_{s'\in \mathcal{S}_U} \delta(s_0, x, s')
p u ( s 0 , x ) = x ∈ Σ ∗ Pr ( from s 0 to unsafe ) = s ′ ∈ S U ∑ δ ( s 0 , x , s ′ )
定义恶意载荷语言集合:
L mal ( s ) = { x ∈ Σ ∗ ∣ ∑ s ′ ∈ S U δ ( s , x , s ′ ) > 0 } \mathcal{L}_{\text{mal}}(s) = \left\{ x\in\Sigma^* \mid \sum_{s'\in \mathcal{S}_U} \delta(s, x, s') > 0 \right\}
L mal ( s ) = { x ∈ Σ ∗ ∣ s ′ ∈ S U ∑ δ ( s , x , s ′ ) > 0 }
对于一轮攻防,可以记:
L mal = L mal ( s 0 ) \mathcal{L}_{\text{mal}} = \mathcal{L}_{\text{mal}}(s_0)
L mal = L mal ( s 0 )
1.2 攻击动作
在前序的建模中,我们直接指定了黑客所使用的特定图灵机,而事实上由于攻防的不对称性,攻击者应当是在一族满足条件的黑客图灵机中进行选择 。下面考虑将攻击者定义为一个资源受限的概率多项式通用图灵机 U \mathcal{U} U ⟨ π ⟩ \langle \pi\rangle ⟨ π ⟩ ⟨ S ⟩ \langle S \rangle ⟨ S ⟩ r r r ⟨ π ⟩ \langle \pi \rangle ⟨ π ⟩ x ← U ( ⟨ π ⟩ , ⟨ S ⟩ , r ) x \leftarrow \mathcal{U}(\langle \pi \rangle, \langle S \rangle, r) x ← U ( ⟨ π ⟩ , ⟨ S ⟩ , r )
定义攻击者为一个受限于多项式时空资源的概率通用图灵机 U A \mathcal{U}_{\mathcal{A}} U A Π \Pi Π ⟨ π ⟩ ∈ Π \langle \pi \rangle \in \Pi ⟨ π ⟩ ∈ Π
在单轮攻防中,攻击者基于当前观测到的环境上下文 ⟨ S ⟩ \langle S \rangle ⟨ S ⟩ ⟨ π ⟩ \langle \pi \rangle ⟨ π ⟩ r r r M A \mathcal{M}_A M A x x x
M A ← U A ( ⟨ π ⟩ , ⟨ S ⟩ , r ) \mathcal{M}_A \leftarrow \mathcal{U}_{\mathcal{A}}(\langle \pi \rangle, \langle S \rangle, r)
M A ← U A ( ⟨ π ⟩ , ⟨ S ⟩ , r )
通用图灵机生成的脚本的资源开销必须满足系统的物理上限:
Φ ( M A ) ⩽ R A \Phi(\mathcal{M}_A) \leqslant \mathcal{R}_{\mathcal{A}}
Φ ( M A ) ⩽ R A
在这一框架下,攻击者生成的载荷分布 D π \mathcal{D}_{\pi} D π ⟨ π ⟩ \langle \pi \rangle ⟨ π ⟩ p p p a a a ⟨ π ⟩ \langle \pi \rangle ⟨ π ⟩
p ( π ) = Pr x ← D π ( x ∈ L mal ) p(\pi) = \Pr_{x \gets \mathcal{D}_{\pi}} (x \in \mathcal{L}_{\text{mal}})
p ( π ) = x ← D π Pr ( x ∈ L mal )
a ( π ) = Pr x ← D π ( x ∈ L D ∩ L mal ) a(\pi) = \Pr_{x \gets \mathcal{D}_{\pi}} (x \in L_D \cap \mathcal{L}_{\text{mal}})
a ( π ) = x ← D π Pr ( x ∈ L D ∩ L mal )
下面我们关注两个语言类 L D L_D L D L mal \mathcal{L}_{\text{mal}} L mal
L D ∩ L mal L_D \cap \mathcal{L}_{\text{mal}} L D ∩ L mal L D − L mal L_D - \mathcal{L}_{\text{mal}} L D − L mal L mal − L D \mathcal{L}_{\text{mal}} - L_D L mal − L D
下面其实就可以走杨义先《安全通论》里面的那套说法,但是我还是觉得有点牵强,就不放上来了。
1.3 资源分析
在攻击方生成并投递载荷 x x x M D \mathcal{M}_D M D M D \mathcal{M}_D M D r D r_{\mathcal{D}} r D x x x M D \mathcal{M}_D M D C 0 , C 1 , … , C k C_0, C_1, \dots, C_k C 0 , C 1 , … , C k ( x , r D ) (x, r_{\mathcal{D}}) ( x , r D )
实际时间消耗 t ( x , r D ) = k t(x, r_{\mathcal{D}}) = k t ( x , r D ) = k 实际空间消耗 s ( x , r D ) = max { ∣ C i ∣ ∣ 0 ⩽ i ⩽ k } s(x, r_{\mathcal{D}}) = \max\{|C_i| \mid 0 \leqslant i \leqslant k\} s ( x , r D ) = max { ∣ C i ∣ ∣ 0 ⩽ i ⩽ k }
由此,定义防守方针对于特定载荷 x x x 资源消耗函数 W M D ( x ) W_{\mathcal{M}_D}(x) W M D ( x )
W M D ( x ) = E r D [ t ( x , r D ) + s ( x , r D ) ] W_{\mathcal{M}_D}(x) = \mathbb{E}_{r_{\mathcal{D}}} \left[ t(x, r_{\mathcal{D}}) + s(x, r_{\mathcal{D}}) \right]
W M D ( x ) = E r D [ t ( x , r D ) + s ( x , r D ) ]
当攻击者以策略 ⟨ π ⟩ \langle \pi \rangle ⟨ π ⟩ D π \mathcal{D}_{\pi} D π 预期资源消耗代价 为:
C M D ( π ) = E x ← D π [ W M D ( x ) ] C_{\mathcal{M}_D}(\pi) = \mathbb{E}_{x \gets \mathcal{D}_{\pi}} \left[ W_{\mathcal{M}_D}(x) \right]
C M D ( π ) = E x ← D π [ W M D ( x ) ]
对于防守方物理资源上限 R D \mathcal{R}_D R D I D o S ( x ) = 1 ⟺ W M D ( x ) > R D \mathbb{I}_{DoS}(x) = 1 \iff W_{\mathcal{M}_D}(x) > \mathcal{R}_D I D o S ( x ) = 1 ⟺ W M D ( x ) > R D x x x 1 1 1 S U \mathcal{S}_U S U
若 W M D ( x ) > R D , 则 ∀ s ∈ S , ∑ s ′ ∈ S U δ ( s , x , s ′ ) = 1 \text{若}\ W_{\mathcal{M}_D}(x) > \mathcal{R}_D, \text{ 则 }\ \forall s \in \mathbb{S}, \sum_{s' \in \mathcal{S}_U} \delta(s, x, s') = 1
若 W M D ( x ) > R D , 则 ∀ s ∈ S , s ′ ∈ S U ∑ δ ( s , x , s ′ ) = 1
此时攻击者通过算法复杂度攻击(如 ReDoS)在物理维度上造成了拒绝服务(DoS)。
2. 受限资源下的绝对防御
在单轮对抗中,若对于任意满足资源约束 Φ ( M A ) ⩽ R A \Phi(\mathcal{M}_A)\leqslant \mathcal{R}_A Φ ( M A ) ⩽ R A M A \mathcal{M}_A M A ψ ( L D ) ⩽ R D \psi(L_D)\leqslant \mathcal{R}_D ψ ( L D ) ⩽ R D M D \mathcal{M}_D M D 0 0 0 M D \mathcal{M}_D M D ( R A , R D ) (\mathcal{R}_A, \mathcal{R}_D) ( R A , R D )
Adv A ( R A , R D ) = max M A : Φ ( M A ) ⩽ R A { E x ← M A [ ( 1 − r R D ( M A ) ) ⋅ p u ( s 0 , x ) ] } = 0 \text{Adv}_{\mathcal{A}}(\mathcal{R}_A, \mathcal{R}_D) = \max_{\mathcal{M}_A:\Phi(\mathcal{M}_A)\leqslant \mathcal{R}_A} \left\{ \mathbb{E}_{x\gets\mathcal{M}_A} \left[ (1-r^{\mathcal{R}_D}(\mathcal{M}_A)) \cdot p_u(s_0, x) \right] \right\} = 0
Adv A ( R A , R D ) = M A : Φ ( M A ) ⩽ R A max { E x ← M A [ ( 1 − r R D ( M A ) ) ⋅ p u ( s 0 , x ) ] } = 0
这里把一次成功的攻击拆解为三个独立的概率事件:
攻击者生成载荷 x x x x ← M A x \leftarrow \mathcal{M}_A x ← M A
防守方未能拦截的概率 ( 1 − r R D ( M A ) ) (1 - r^{\mathcal{R}_D}(\mathcal{M}_A)) ( 1 − r R D ( M A ) ) r R D ( M A ) = Pr x ← M A ( x ∈ L D ∣ ψ ( L D ) ⩽ R D ) r^{\mathcal{R}_D}(\mathcal{M}_A) = \Pr_{x\gets \mathcal{M}_A}(x\in L_D \mid \psi(L_D) \leqslant \mathcal{R}_D) r R D ( M A ) = Pr x ← M A ( x ∈ L D ∣ ψ ( L D ) ⩽ R D )
载荷触发系统非安全状态转移的概率 p u ( s 0 , x ) p_u(s_0, x) p u ( s 0 , x )
要构建 ( R A , R D ) (\mathcal{R}_A, \mathcal{R}_D) ( R A , R D ) M D \mathcal{M}_D M D
由概率的非负性可得,要么 r R D = 1 r^{\mathcal{R}_D} = 1 r R D = 1 ∀ x ∈ Supp ( M A ) \forall x\in \text{Supp}(\mathcal{M}_A) ∀ x ∈ Supp ( M A ) p u ( s 0 , x ) = 0 p_u(s_0, x) = 0 p u ( s 0 , x ) = 0 r R D = 1 r^{\mathcal{R}_D} = 1 r R D = 1 ∀ x ∈ Supp ( M A ) \forall x\in \text{Supp}(\mathcal{M}_A) ∀ x ∈ Supp ( M A ) x ∈ L D x\in L_D x ∈ L D Supp ( M A ) ⊆ L D \text{Supp}(\mathcal{M}_A) \subseteq L_D Supp ( M A ) ⊆ L D ∀ x ∈ Supp ( M A ) \forall x\in \text{Supp}(\mathcal{M}_A) ∀ x ∈ Supp ( M A ) p u ( s 0 , x ) = 0 p_u(s_0, x) = 0 p u ( s 0 , x ) = 0 ∀ x ∈ Supp ( M A ) , ∀ s ′ ∈ S U \forall x\in \text{Supp}(\mathcal{M}_A),\ \forall s'\in\mathcal{S}_U ∀ x ∈ Supp ( M A ) , ∀ s ′ ∈ S U δ ( s 0 , x , s ′ ) = 0 \delta(s_0, x, s') = 0 δ ( s 0 , x , s ′ ) = 0 Supp ( M A ) ∩ L mal = ∅ \text{Supp}(\mathcal{M}_A)\cap \mathcal{L}_{\text{mal}} = \emptyset Supp ( M A ) ∩ L mal = ∅ ( R A , R D ) (\mathcal{R}_A, \mathcal{R}_D) ( R A , R D ) M D \mathcal{M}_D M D M D \mathcal{M}_D M D Supp ( M A ) ∩ ( L mal − L D ) = ∅ \text{Supp}(\mathcal{M}_A)\cap(\mathcal{L}_{\text{mal}} - L_D) = \emptyset Supp ( M A ) ∩ ( L mal − L D ) = ∅
下面应当研究:L mal − L D \mathcal{L}_{\text{mal}} - L_D L mal − L D
注意到防守方受到资源 R D \mathcal{R}_D R D N = log R D N = \log \mathcal{R}_D N = log R D
要计算长度为 N N N
L gap = ( L mal ∖ L D ) ∩ Σ N L_{\text{gap}} = (\mathcal{L}_{\text{mal}} \setminus L_D) \cap \Sigma^N
L gap = ( L mal ∖ L D ) ∩ Σ N
为了计算 ∣ L gap ∣ ( N ) |L_{\text{gap}}|^{(N)} ∣ L gap ∣ ( N )
G mal = ( S , E sys ) G_{\text{mal}} = (\mathbb{S}, E_{\text{sys}}) G mal = ( S , E sys ) S U \mathcal{S}_U S U G D − = ( V D , E D − ) G_{\mathcal{D}}^- = (V_{\mathcal{D}}, E_{\mathcal{D}}^-) G D − = ( V D , E D − ) 0 0 0 F D − F_{\mathcal{D}}^- F D −
构建乘积自动机图 G mix = G mal × G D − G_{\text{mix}} = G_{\text{mal}} \times G_{\mathcal{D}}^- G mix = G mal × G D −
顶点集:V mix = S × V D V_{\text{mix}} = \mathbb{S} \times V_{\mathcal{D}} V mix = S × V D
边集:如果在给定字符 c ∈ Σ c \in \Sigma c ∈ Σ
邻接矩阵:设 A A A G mix G_{\text{mix}} G mix A i , j A_{i,j} A i , j i i i j j j
设指示向量 u T u^T u T ( s 0 , q 0 ) (s_0, q_0) ( s 0 , q 0 ) v v v S U × F D − \mathcal{S}_U \times F_{\mathcal{D}}^- S U × F D − N N N N N N
∣ L gap ∣ ( N ) = u T A N v |L_{\text{gap}}|^{(N)} = u^T A^N v
∣ L gap ∣ ( N ) = u T A N v
就接下来采用 Perron-Frobenius 定理和 Jordan 分解来求 A N A^N A N
对邻接矩阵 A A A
A = P J P − 1 A = P J P^{-1}
A = P J P − 1
其中,P P P J J J J J J J = diag ( J 1 , J 2 , … , J k ) J = \text{diag}(J_1, J_2, \dots, J_k) J = diag ( J 1 , J 2 , … , J k ) λ i \lambda_i λ i m i m_i m i J i J_i J i N i N_i N i
J i = λ i I + N i J_i = \lambda_i I + N_i
J i = λ i I + N i
其中 N i N_i N i 1 1 1 0 0 0
对于单个 Jordan 块,由于 λ i I \lambda_i I λ i I N i N_i N i
J i N = ( λ i I + N i ) N = ∑ j = 0 N ( N j ) λ i N − j N i j J_i^N = (\lambda_i I + N_i)^N = \sum_{j=0}^N \binom{N}{j} \lambda_i^{N-j} N_i^j
J i N = ( λ i I + N i ) N = j = 0 ∑ N ( j N ) λ i N − j N i j
因为当 j ⩾ m i j \geqslant m_i j ⩾ m i N i j = 0 N_i^j = \mathbf{0} N i j = 0
J i N = ∑ j = 0 min ( N , m i − 1 ) ( N j ) λ i N − j N i j J_i^N = \sum_{j=0}^{\min(N, m_i-1)} \binom{N}{j} \lambda_i^{N-j} N_i^j
J i N = j = 0 ∑ m i n ( N , m i − 1 ) ( j N ) λ i N − j N i j
当 N N N J i N J_i^N J i N j = m i − 1 j = m_i-1 j = m i − 1
( N m i − 1 ) λ i N − ( m i − 1 ) \binom{N}{m_i-1} \lambda_i^{N-(m_i-1)}
( m i − 1 N ) λ i N − ( m i − 1 )
此时回到总路径数公式:
∣ L gap ∣ ( N ) = u T ( P J N P − 1 ) v |L_{\text{gap}}|^{(N)} = u^T (P J^N P^{-1}) v
∣ L gap ∣ ( N ) = u T ( P J N P − 1 ) v
令行向量 c T = u T P c^T = u^T P c T = u T P d = P − 1 v d = P^{-1} v d = P − 1 v J N J^N J N N → ∞ N \to \infty N → ∞ N N N A N A^N A N A A A λ max \lambda_{\max} λ m a x
在渐近复杂度下,常数系数与低阶项被忽略。组合数 ( N m − 1 ) ≈ N m − 1 ( m − 1 ) ! \binom{N}{m-1} \approx \frac{N^{m-1}}{(m-1)!} ( m − 1 N ) ≈ ( m − 1 ) ! N m − 1 N N N N m − 1 N^{m-1} N m − 1 N N N
∣ L gap ∣ ( N ) = Θ ( N m − 1 λ max N − m + 1 ) ∼ Θ ( log ( R D ) m − 1 ⋅ R D log ( λ max ) ) |L_{\text{gap}}|^{(N)} = \Theta \left( N^{m-1} \lambda_{\max}^{N - m + 1} \right) \sim \Theta \left( \log(\mathcal{R}_D)^{m-1} \cdot \mathcal{R}_D^{\log(\lambda_{\max})} \right)
∣ L gap ∣ ( N ) = Θ ( N m − 1 λ m a x N − m + 1 ) ∼ Θ ( log ( R D ) m − 1 ⋅ R D l o g ( λ m a x ) )
此时,我们可以看到:
若 λ max = 0 \lambda_{\max} = 0 λ m a x = 0 G mix G_{\text{mix}} G mix
若 λ max = 1 \lambda_{\max} = 1 λ m a x = 1 Θ ( N m − 1 ) \Theta(N^{m-1}) Θ ( N m − 1 )
若 λ max > 1 \lambda_{\max} > 1 λ m a x > 1 N N N Θ ( λ max N ) \Theta(\lambda_{\max}^N) Θ ( λ m a x N )
这里 λ max \lambda_{\max} λ m a x
3. 灰盒模型
现实中肯定不是在 Σ N \Sigma^N Σ N ∣ Σ ∣ − N |\Sigma|^{-N} ∣ Σ ∣ − N 攻击者虽然初始时没有完整的图 G mix G_{\text{mix}} G mix w 0 = ∅ w_0 = \emptyset w 0 = ∅ w w w t t t G obs ( t ) ⊆ G mix G_{\text{obs}}^{(t)} \subseteq G_{\text{mix}} G obs ( t ) ⊆ G mix
当黑客投递载荷 x x x τ ( x ) \tau(x) τ ( x )
G obs ( t ) = G obs ( t − 1 ) ∪ τ ( x t ) G_{\text{obs}}^{(t)} = G_{\text{obs}}^{(t-1)} \cup \tau(x_t)
G obs ( t ) = G obs ( t − 1 ) ∪ τ ( x t )
灰盒攻击者投递的分布是一个随着知识库动态更新的条件概率分布:
D fuzz ( ⋅ ∣ G obs ( t ) ) \mathcal{D}_{\text{fuzz}}(\cdot \mid G_{\text{obs}}^{(t)})
D fuzz ( ⋅ ∣ G obs ( t ) )
啊这里定义了后面其实就没有用这个定义。
3.1 灰盒攻击策略
设 G mix = ( V , E ) G_{\text{mix}} = (V, E) G mix = ( V , E ) s 0 s_0 s 0 s k ∈ S U s_k \in \mathcal{S}_U s k ∈ S U ρ = ( s 0 , ⋯ , s k ) \rho = (s_0, \cdots, s_k) ρ = ( s 0 , ⋯ , s k )
定义一个随机化 Fuzzer :
种子队列 Q \mathbb{Q} Q ∣ S ∣ |\mathbb{S}| ∣ S ∣ ∣ Q ∣ ⩽ ∣ S ∣ |\mathbb{Q}| \leqslant |\mathbb{S}| ∣ Q ∣ ⩽ ∣ S ∣ 纯随机调度 :在每一轮测试 t t t Q \mathbb{Q} Q s i s_i s i P select ( s i ) = 1 / ∣ Q ∣ ⩾ 1 / ∣ S ∣ P_{\text{select}}(s_i) = 1/|\mathbb{Q}| \geqslant 1/|\mathbb{S}| P select ( s i ) = 1 / ∣ Q ∣ ⩾ 1 / ∣ S ∣ 纯随机变异 :假设从 s i s_i s i s i + 1 s_{i+1} s i + 1 c i c_i c i c i c_i c i P mutate = ∣ Σ ∣ − c i P_{\text{mutate}} = |\Sigma|^{-c_i} P mutate = ∣ Σ ∣ − c i c i c_i c i ( N − c i k − c i ) / ( N k ) \binom{N-c_i}{k-c_i}/\binom{N}{k} ( k − c i N − c i ) / ( k N )
容易指出 :在任意一轮 t t t s i s_i s i s i + 1 s_{i+1} s i + 1 p i p_i p i
p i = P select ( s i ) ⋅ P mutate ⩾ 1 ∣ S ∣ ⋅ ∣ Σ ∣ c i p_i = P_{\text{select}}(s_i) \cdot P_{\text{mutate}} \geqslant \frac{1}{|\mathbb{S}| \cdot |\Sigma|^{c_i}}
p i = P select ( s i ) ⋅ P mutate ⩾ ∣ S ∣ ⋅ ∣ Σ ∣ c i 1
设随机变量 X i X_i X i s i s_i s i s i + 1 s_{i+1} s i + 1 独立的伯努利试验 ,X i X_i X i p i p_i p i 几何分布 :
X i ∼ Geo ( p i ) X_i \sim \text{Geo}(p_i)
X i ∼ Geo ( p i )
几何分布的数学期望 为:
E [ X i ] = 1 p i ⩽ ∣ S ∣ ⋅ ∣ Σ ∣ c i \mathbb{E}[X_i] = \frac{1}{p_i} \leqslant |\mathbb{S}| \cdot |\Sigma|^{c_i}
E [ X i ] = p i 1 ⩽ ∣ S ∣ ⋅ ∣ Σ ∣ c i
设突破整条长度为 k k k T hit T_{\text{hit}} T hit T hit = ∑ i = 0 k − 1 X i T_{\text{hit}} = \sum_{i=0}^{k-1} X_i T hit = ∑ i = 0 k − 1 X i 总期望时间 为:
E [ T hit ] = ∑ i = 0 k − 1 E [ X i ] ≤ ∣ S ∣ ∑ i = 0 k − 1 ∣ Σ ∣ c i \mathbb{E}[T_{\text{hit}}] = \sum_{i=0}^{k-1} \mathbb{E}[X_i] \le |\mathbb{S}| \sum_{i=0}^{k-1} |\Sigma|^{c_i}
E [ T hit ] = i = 0 ∑ k − 1 E [ X i ] ≤ ∣ S ∣ i = 0 ∑ k − 1 ∣ Σ ∣ c i
设所有局部突破中最难的一步对应的成功率 为:
p min = min i ( p i ) = 1 ∣ S ∣ ∣ Σ ∣ c max p_{\min} = \min_i (p_i) = \frac{1}{|\mathbb{S}| |\Sigma|^{c_{\max}}}
p m i n = i min ( p i ) = ∣ S ∣ ∣ Σ ∣ c m a x 1
那么 T hit T_{\text{hit}} T hit 负二项分布 NB ( k , p min ) \text{NB}(k, p_{\min}) NB ( k , p m i n ) k k k Geo ( p min ) \text{Geo}(p_{\min}) Geo ( p m i n ) Chernoff 不等式 ,有 ∀ δ > 0 \forall \delta > 0 ∀ δ > 0
Pr ( T hit > ( 1 + δ ) k p min ) ⩽ exp ( − δ 2 2 ( 1 + δ ) k ) \Pr \left( T_{\text{hit}} > (1+\delta) \frac{k}{p_{\min}} \right) \leqslant \exp\left( - \frac{\delta^2}{2(1+\delta)} k \right)
Pr ( T hit > ( 1 + δ ) p m i n k ) ⩽ exp ( − 2 ( 1 + δ ) δ 2 k )
设分配给灰盒攻击者的资源为 R A grey = ( 1 + δ ) k p min \mathcal{R}_A^{\text{grey}} = (1+\delta)\frac{k}{p_{\min}} R A grey = ( 1 + δ ) p m i n k 若要保证随机化 Fuzzer 能够以概率 ( 1 − ε ) (1-\varepsilon) ( 1 − ε )
ε = exp ( − δ 2 2 ( 1 + δ ) k ) \varepsilon = \exp\left( - \frac{\delta^2}{2(1+\delta)} k \right)
ε = exp ( − 2 ( 1 + δ ) δ 2 k )
即:
δ ≈ 2 ln ( 1 / ε ) k \delta \approx \sqrt{\frac{2\ln(1/\varepsilon)}{k}}
δ ≈ k 2 ln ( 1 / ε )
最后我们得到下述结论:对任意状态空间为 S \mathbb{S} S k k k c max c_{\max} c m a x ( 1 − ε ) (1 - \varepsilon) ( 1 − ε )
R A grey ⩽ O ( k ⋅ ∣ S ∣ ⋅ ∣ Σ ∣ c max ⋅ ln ( 1 / ε ) ) \mathcal{R}_A^{\text{grey}} \leqslant O\left( k \cdot |\mathbb{S}| \cdot |\Sigma|^{c_{\max}} \cdot \ln(1/\varepsilon) \right)
R A grey ⩽ O ( k ⋅ ∣ S ∣ ⋅ ∣ Σ ∣ c m a x ⋅ ln ( 1 / ε ) )
反过来,只要灰盒攻击者的资源满足 R A grey > k ⋅ ∣ S ∣ ⋅ ∣ Σ ∣ c max \mathcal{R}_A^{\text{grey}} > k \cdot |\mathbb{S}| \cdot |\Sigma|^{c_{\max}} R A grey > k ⋅ ∣ S ∣ ⋅ ∣ Σ ∣ c m a x
Pr ( succeed ) ⩾ 1 − exp ( − ( R A ∣ S ∣ ⋅ ∣ Σ ∣ c max ⋅ k − 1 ) 2 2 ⋅ R A ∣ S ∣ ⋅ ∣ Σ ∣ c max ⋅ k ⋅ k ) \Pr(\text{succeed}) \geqslant 1 - \exp\left( - \frac{ \left( \frac{\mathcal{R}_A}{|\mathbb{S}| \cdot |\Sigma|^{c_{\max}} \cdot k} - 1 \right)^2 }{ 2 \cdot \frac{\mathcal{R}_A}{|\mathbb{S}| \cdot |\Sigma|^{c_{\max}} \cdot k} } \cdot k \right)
Pr ( succeed ) ⩾ 1 − exp ⎝ ⎜ ⎜ ⎛ − 2 ⋅ ∣ S ∣ ⋅ ∣ Σ ∣ c m a x ⋅ k R A ( ∣ S ∣ ⋅ ∣ Σ ∣ c m a x ⋅ k R A − 1 ) 2 ⋅ k ⎠ ⎟ ⎟ ⎞
3.2 受限资源防御下攻击导向的随机化灰盒分析
我们把我们的视角从整个图 G mix G_{\text{mix}} G mix L gap ( N ) L_{\text{gap}}^{(N)} L gap ( N ) 。这时资源约束仍然为 N = log R D N = \log \mathcal{R}_D N = log R D ∣ L gap ∣ ( N ) = Θ ( N m − 1 λ max N − m + 1 ) |L_{\text{gap}}|^{(N)} = \Theta(N^{m-1}\lambda_{\max}^{N-m+1}) ∣ L gap ∣ ( N ) = Θ ( N m − 1 λ m a x N − m + 1 )
设 Fuzzer 突破整个 L gap L_{\text{gap}} L gap k k k i i i s i s_i s i c i c_i c i L gap L_{\text{gap}} L gap d i d_i d i
P mutate , i = d i ⋅ ∣ Σ ∣ − c i P_{\text{mutate}, i} = d_i \cdot |\Sigma|^{-c_i}
P mutate , i = d i ⋅ ∣ Σ ∣ − c i
同时注意到 :
∏ i = 1 k d i = ∣ L gap ∣ ( N ) = Θ ( N m − 1 λ max N ) \prod_{i=1}^k d_i = |L_{\text{gap}}|^{(N)} = \Theta(N^{m-1}\lambda_{\max}^N)
i = 1 ∏ k d i = ∣ L gap ∣ ( N ) = Θ ( N m − 1 λ m a x N )
以及同时,载荷总长度守恒 :
∑ i = 1 k c i = N \sum_{i=1}^k c_i = N
i = 1 ∑ k c i = N
Fuzzer 在第 i i i p i = 1 ∣ Q ∣ ⋅ d i ∣ Σ ∣ − c i p_i = \frac{1}{|\mathbb{Q}|} \cdot d_i |\Sigma|^{-c_i} p i = ∣ Q ∣ 1 ⋅ d i ∣ Σ ∣ − c i ∣ Q ∣ ≤ ∣ S ∣ |\mathbb{Q}| \le |\mathbb{S}| ∣ Q ∣ ≤ ∣ S ∣
E [ X i ] = 1 p i ⩽ ∣ S ∣ ⋅ ∣ Σ ∣ c i d i \mathbb{E}[X_i] = \frac{1}{p_i} \leqslant |\mathbb{S}| \cdot \frac{|\Sigma|^{c_i}}{d_i}
E [ X i ] = p i 1 ⩽ ∣ S ∣ ⋅ d i ∣ Σ ∣ c i
完成整个 L gap L_{\text{gap}} L gap μ \mu μ :
μ = ∑ i = 1 k E [ X i ] ≤ ∣ S ∣ ∑ i = 1 k ∣ Σ ∣ c i d i \mu = \sum_{i=1}^k \mathbb{E}[X_i] \le |\mathbb{S}| \sum_{i=1}^k \frac{|\Sigma|^{c_i}}{d_i}
μ = i = 1 ∑ k E [ X i ] ≤ ∣ S ∣ i = 1 ∑ k d i ∣ Σ ∣ c i
总和往往被瓶颈控制 ,设对于 b b b
∣ Σ ∣ c b d b = max 1 ≤ i ≤ k ( ∣ Σ ∣ c i d i ) \frac{|\Sigma|^{c_b}}{d_b} = \max_{1 \le i \le k} \left( \frac{|\Sigma|^{c_i}}{d_i} \right)
d b ∣ Σ ∣ c b = 1 ≤ i ≤ k max ( d i ∣ Σ ∣ c i )
即:
μ = Θ ( ∣ S ∣ ⋅ ∣ Σ ∣ c b d b ) \mu = \Theta \left( |\mathbb{S}| \cdot \frac{|\Sigma|^{c_b}}{d_b} \right)
μ = Θ ( ∣ S ∣ ⋅ d b ∣ Σ ∣ c b )
同理可得:
Pr ( success ) ⩾ 1 − exp ( − ( R A − μ ) 2 2 ⋅ R A ⋅ μ ⋅ k ) \Pr(\text{success}) \geqslant 1 - \exp\left( - \frac{ ( \mathcal{R}_A - \mu )^2 }{ 2 \cdot \mathcal{R}_A \cdot \mu } \cdot k \right)
Pr ( success ) ⩾ 1 − exp ( − 2 ⋅ R A ⋅ μ ( R A − μ ) 2 ⋅ k )
中间尝试引入 λ max \lambda_{\max} λ m a x λ max \lambda_{\max} λ m a x 系统有多危险,从来不取决于它包含了多少个高危漏洞,而仅仅取决于通往这些漏洞的最短路径上,最容易被绕过的那道门槛有多低。 额,当然你硬要说瓶颈间接依赖于 λ max \lambda_{\max} λ m a x
看起来好像灰盒测试不如白盒测试(O ( ∣ V ∣ + ∣ E ∣ ) O(|V| + |E|) O ( ∣ V ∣ + ∣ E ∣ )
A. 附:攻击信道建模
下面的讨论更加的启发式,且啊啊啊确实或多或少有强行解释的嫌疑。。。
A.1 基本建模
根据攻击信道模型,我们可以将攻击者和防御者的状态用概率矩阵和信道逻辑进行描述。
举例一些具体的场景常常便于理解:
X = 0 X=0 X = 0 Y = 0 Y=0 Y = 0 X = 0 X = 0 X = 0 Z = 0 Z = 0 Z = 0 X = 0 X=0 X = 0 Y = 1 Y=1 Y = 1 X = 0 X = 0 X = 0 Z = 1 Z = 1 Z = 1 X = 1 X=1 X = 1 Y = 0 Y=0 Y = 0 X = 1 X = 1 X = 1 Z = 1 Z = 1 Z = 1 X = 1 X=1 X = 1 Y = 1 Y=1 Y = 1 X = 1 X = 1 X = 1 Z = 0 Z = 0 Z = 0
该攻击过程抽象为一个带有加性噪声的通信信道:
信道输入 :攻击者盲自评 X X X 加性噪声 :防御者盲自评 Y Y Y 信道输出 :攻击者成功攻击 Z = X ⊕ Y Z = X \oplus Y Z = X ⊕ Y
p p p q q q a a a Pr ( X = 1 , Y = 1 ) \Pr(X=1, Y=1) Pr ( X = 1 , Y = 1 )
考虑黑客和红客都足够理性,接下来我们应当明确 p p p q q q
对于 p p p :黑客认为(盲自评)自己成功的概率是 p p p p p p 1 − p 1-p 1 − p p p p p p p 对于 q q q :红客认为(盲自评)自己防守(拦截)成功的概率是 q q q q q q 1 − q 1-q 1 − q q q q q q q q q q
那么 a a a 黑客改变 a a a 备环境感知与威胁情报获取 的能力,他能通过探测主动将其攻击行为与防守方的盲区产生关联。也就是说,黑客在想,自己产生的攻击,到底需不需要和红客的防守策略等等产生关联 。
A.2 攻击信道容量计算
对于黑客(攻击方)来说,红客盲自评为成功的概率他无法控制,因此视为常量,这时问题就转化为:当红客的防守成功概率 q q q C C C p p p a a a
根据 PPT 中给出的公式:
I ( X , Z ) = d log d ( 1 − p ) ( a + d ) + c log c ( 1 − p ) ( b + c ) + a log a p ( a + d ) + b log b p ( b + c ) I(X,Z) = d\log\frac{d}{(1-p)(a+d)} + c\log\frac{c}{(1-p)(b+c)} + a\log\frac{a}{p(a+d)} + b\log\frac{b}{p(b+c)}
I ( X , Z ) = d log ( 1 − p ) ( a + d ) d + c log ( 1 − p ) ( b + c ) c + a log p ( a + d ) a + b log p ( b + c ) b
其中 d = 1 + a − p − q d = 1 + a - p - q d = 1 + a − p − q c = q − a c = q - a c = q − a
注:下述记号 I q ( p , a ) I_{q}(p, a) I q ( p , a ) q q q p , a p, a p , a
对联合概率 a a a
注意到 max p , a I ( p , a ) = max p ( max a I ( p , a ) ) \max\limits_{p, a}I(p, a) = \max\limits_{p}(\max\limits_{a}I(p, a)) p , a max I ( p , a ) = p max ( a max I ( p , a ) ) p p p 对 a a a :
此时:
I q ( p , a ) = d log d ( 1 − p ) Z 0 + c log c ( 1 − p ) Z 1 + a log a p Z 0 + b log b p Z 1 I_{q}(p, a) = d \log \frac{d}{(1-p)Z_0} + c \log \frac{c}{(1-p)Z_1} + a \log \frac{a}{p Z_0} + b \log \frac{b}{p Z_1}
I q ( p , a ) = d log ( 1 − p ) Z 0 d + c log ( 1 − p ) Z 1 c + a log p Z 0 a + b log p Z 1 b
其中,Z 0 = 1 − p − q + 2 a Z_0 = 1-p-q+2a Z 0 = 1 − p − q + 2 a Z 1 = p + q − 2 a Z_1 = p+q-2a Z 1 = p + q − 2 a b = p − a b=p-a b = p − a c = q − a c=q-a c = q − a d = 1 − p − q + a d=1-p-q+a d = 1 − p − q + a a a a
∂ I q ( p , a ) ∂ a = log ( ( p + q − 2 a ) 2 ( 1 − p − q + 2 a ) 2 ⋅ a ( 1 − p − q + a ) ( p − a ) ( q − a ) ) = 0 \frac{\partial I_{q}(p, a)}{\partial a} = \log \left( \frac{(p+q-2a)^2}{(1-p-q+2a)^2} \cdot \frac{a(1-p-q+a)}{(p-a)(q-a)} \right) = 0
∂ a ∂ I q ( p , a ) = log ( ( 1 − p − q + 2 a ) 2 ( p + q − 2 a ) 2 ⋅ ( p − a ) ( q − a ) a ( 1 − p − q + a ) ) = 0
展开得:
− ( 1 − 2 p ) ( 1 − 2 q ) a 2 + ( 1 − p − q ) ( p + q − 4 p q ) a − p q ( 1 − p − q ) 2 = 0 -(1-2p)(1-2q)a^2 + (1-p-q)(p+q-4pq)a - pq(1-p-q)^2 = 0
− ( 1 − 2 p ) ( 1 − 2 q ) a 2 + ( 1 − p − q ) ( p + q − 4 p q ) a − p q ( 1 − p − q ) 2 = 0
其中 Δ = [ ( 1 − p − q ) ( p − q ) ] 2 \Delta = [(1-p-q)(p-q)]^2 Δ = [ ( 1 − p − q ) ( p − q ) ] 2
得到两个解析解:
a 1 = q ( 1 − p − q ) 1 − 2 q , a 2 = p ( 1 − p − q ) 1 − 2 p a_1 = \frac{q(1-p-q)}{1-2q}, \quad a_2 = \frac{p(1-p-q)}{1-2p}
a 1 = 1 − 2 q q ( 1 − p − q ) , a 2 = 1 − 2 p p ( 1 − p − q )
注意到 a a a p p p q q q
{ b = p − a > 0 ⇒ a < p c = q − a > 0 ⇒ a < q d = 1 − p − q + a > 0 ⇒ a > p + q − 1 \begin{cases}
b = p - a > 0 \Rightarrow a < p\\
c = q - a > 0 \Rightarrow a < q\\
d = 1 - p - q + a > 0 \Rightarrow a > p + q - 1
\end{cases}
⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ b = p − a > 0 ⇒ a < p c = q − a > 0 ⇒ a < q d = 1 − p − q + a > 0 ⇒ a > p + q − 1
即:
max ( 0 , p + q − 1 ) < a < min ( p , q ) \max(0, p+q-1) < a < \min(p, q)
max ( 0 , p + q − 1 ) < a < min ( p , q )
然而:
a 1 − p = ( q − p ) ( 1 − q ) 1 − 2 q , a 1 − q = q ( q − p ) 1 − 2 q a_1 - p = \frac{(q-p)(1-q)}{1-2q}, \quad a_1 - q = \frac{q(q-p)}{1-2q}
a 1 − p = 1 − 2 q ( q − p ) ( 1 − q ) , a 1 − q = 1 − 2 q q ( q − p )
a 2 − p = p ( p − q ) 1 − 2 p , a 2 − q = ( p − q ) ( 1 − p ) 1 − 2 p a_2 - p = \frac{p(p-q)}{1-2p}, \quad a_2 - q = \frac{(p-q)(1-p)}{1-2p}
a 2 − p = 1 − 2 p p ( p − q ) , a 2 − q = 1 − 2 p ( p − q ) ( 1 − p )
这意味着 a 1 a_1 a 1 a 2 a_2 a 2 p p p q q q a a a I ( a ) I(a) I ( a ) a a a max ( 0 , p + q − 1 ) \max(0, p+q-1) max ( 0 , p + q − 1 ) min ( p , q ) \min(p, q) min ( p , q )
简单理解如下:
a = min ( p , q ) a = \min(p, q) a = min ( p , q ) X = 1 X=1 X = 1 Y = 1 Y=1 Y = 1 a = max ( 0 , p + q − 1 ) a = \max(0, p+q-1) a = max ( 0 , p + q − 1 ) Pr ( X = 1 , Y = 1 ) \Pr(X=1, Y=1) Pr ( X = 1 , Y = 1 ) 0 0 0
那么 a a a
当 a a a
当 a = 0 a = 0 a = 0 :即 Pr ( X = 1 , Y = 1 ) = 0 \Pr(X=1, Y=1) = 0 Pr ( X = 1 , Y = 1 ) = 0 防守系统的机密性被破坏 。当 a = p + q − 1 a = p + q - 1 a = p + q − 1 :这说明红客或者黑客的动静都有点太大了,黑客绝对隐蔽是不太可能了,但是黑客这时还是尽可能小地去避免重叠,耗费防守方的一部分资源。这时候我们计算:Pr ( Y = 1 ∣ X = 0 ) = Pr ( X = 0 , Y = 1 ) Pr ( X = 0 ) = q − a 1 − p = q − ( p + q − 1 ) 1 − p = 1 − p 1 − p = 100 % \Pr(Y=1 \mid X=0) = \frac{\Pr(X=0, Y=1)}{\Pr(X=0)} = \frac{q - a}{1 - p} = \frac{q - (p+q-1)}{1 - p} = \frac{1 - p}{1 - p} = 100\%
Pr ( Y = 1 ∣ X = 0 ) = Pr ( X = 0 ) Pr ( X = 0 , Y = 1 ) = 1 − p q − a = 1 − p q − ( p + q − 1 ) = 1 − p 1 − p = 1 0 0 %
发现在黑客没有发动真实攻击(X = 0 X=0 X = 0 Y = 1 Y=1 Y = 1 防守系统的可用性被破坏 。
当 a a a
当 a = p a = p a = p :这时 p ⩽ q p \leqslant q p ⩽ q q → 1 q \to 1 q → 1 a a a p p p 防守系统遭受此时该黑客能够给到的最大威胁当量,防守系统的资源被消耗 。当 a = q a = q a = q :这时 p ⩾ q p \geqslant q p ⩾ q 防守系统的可用性被最大化破坏,机密性也遭受响应破坏。
对于固定水平的黑客而言,他要么硬刚,要么暗度陈仓。
也就是说:
max a I q ( p , a ) ∈ { I q ( p , 0 ) , I q ( p , p + q − 1 ) , I q ( p , p ) , I q ( p , q ) } \max\limits_{a}{I_q(p, a)}\in \left\{I_q\left(p, 0\right), I_q\left(p, p+q-1\right), I_q\left(p, p\right), I_q\left(p, q\right)\right\}
a max I q ( p , a ) ∈ { I q ( p , 0 ) , I q ( p , p + q − 1 ) , I q ( p , p ) , I q ( p , q ) }
根据观察 max p , a I ( p , a ) = max p ( max a I ( p , a ) ) \max\limits_{p, a}I(p, a) = \max\limits_{p}(\max\limits_{a}I(p, a)) p , a max I ( p , a ) = p max ( a max I ( p , a ) )
max p , a I q ( p , a ) ∈ { max p I q ( p , 0 ) , max p I q ( p , p + q − 1 ) , max p I q ( p , p ) , max p I q ( p , q ) } \max\limits_{p, a}{I_q(p, a)}\in \left\{\max\limits_{p}I_q\left(p, 0\right), \max\limits_{p}I_q\left(p, p+q-1\right), \max\limits_{p}I_q\left(p, p\right), \max\limits_{p}I_q\left(p, q\right)\right\}
p , a max I q ( p , a ) ∈ { p max I q ( p , 0 ) , p max I q ( p , p + q − 1 ) , p max I q ( p , p ) , p max I q ( p , q ) }
对黑客水平 p p p
下面,就让我们来进行分类讨论吧!
当 p + q ⩽ 1 p + q\leqslant 1 p + q ⩽ 1 a = 0 a = 0 a = 0
此时:
I ( q , p ) = I q ( p , 0 ) = − ( 1 − p ) log ( 1 − p ) + q log q − ( p + q ) log ( p + q ) I(q, p) = I_q(p, 0) = -(1-p)\log(1-p)+q\log q - (p+q)\log(p+q)
I ( q , p ) = I q ( p , 0 ) = − ( 1 − p ) log ( 1 − p ) + q log q − ( p + q ) log ( p + q )
即得:
d I q d p = log ( 1 − p p + q ) = 0 \frac{dI_q}{dp} = \log \left( \frac{1-p}{p+q} \right) = 0
d p d I q = log ( p + q 1 − p ) = 0
即:
p a = 0 ∗ = 1 − q 2 p^*_{a=0} = \frac{1-q}{2}
p a = 0 ∗ = 2 1 − q
此时的互信息为:
I ( q ) = ( q + 1 ) ( 1 − log ( 1 + q ) ) + q log q I(q)=(q+1)(1-\log(1+q))+q\log q
I ( q ) = ( q + 1 ) ( 1 − log ( 1 + q ) ) + q log q
当 p + q ⩾ 1 p + q\geqslant 1 p + q ⩾ 1 a = p + q − 1 a = p + q - 1 a = p + q − 1
此时:
I ( q , p ) = I q ( p , p + q − 1 ) = ( 1 − q ) log ( 1 − q ) − p log p − ( 2 − p − q ) log ( 2 − p − q ) I(q, p) = I_q(p, p+q-1) = (1-q)\log(1-q)-p\log p-(2-p-q)\log(2-p-q)
I ( q , p ) = I q ( p , p + q − 1 ) = ( 1 − q ) log ( 1 − q ) − p log p − ( 2 − p − q ) log ( 2 − p − q )
即得:
d I d p = log ( 2 − p − q p ) = 0 \frac{dI}{dp} = \log \left( \frac{2-p-q}{p} \right) = 0
d p d I = log ( p 2 − p − q ) = 0
即:
p ( a = p + q − 1 ) ∗ = p = 1 − q 2 p^*_{(a = p + q - 1)} = p=1-\dfrac{q}{2}
p ( a = p + q − 1 ) ∗ = p = 1 − 2 q
此时的互信息为:
I ( q ) = ( 2 − q ) ( 1 − log ( 2 − q ) ) + ( 1 − q ) log ( 1 − q ) I(q)=(2-q)(1-\log(2-q))+(1-q)\log(1-q)
I ( q ) = ( 2 − q ) ( 1 − log ( 2 − q ) ) + ( 1 − q ) log ( 1 − q )
当 p ⩽ q p \leqslant q p ⩽ q a = p a = p a = p
此时:
I ( q , p ) = I q ( p , p ) = ( 1 − q ) log ( 1 − q ) − ( 1 − p ) log ( 1 − p ) − ( 1 + p − q ) log ( 1 + p − q ) I(q, p) = I_q(p, p) = (1-q)\log(1-q)-(1-p)\log(1-p)-(1+p-q)\log(1+p-q)
I ( q , p ) = I q ( p , p ) = ( 1 − q ) log ( 1 − q ) − ( 1 − p ) log ( 1 − p ) − ( 1 + p − q ) log ( 1 + p − q )
即得:
d I d p = log ( 1 − p 1 + p − q ) = 0 \frac{dI}{dp} = \log \left( \frac{1-p}{1+p-q} \right) = 0
d p d I = log ( 1 + p − q 1 − p ) = 0
即:
p ( a = p ) ∗ = q 2 p^*_{(a = p)} = \frac{q}{2}
p ( a = p ) ∗ = 2 q
此时的互信息为:
I ( q ) = ( 2 − q ) ( 1 − log 2 ( 2 − q ) ) + ( 1 − q ) log 2 ( 1 − q ) I(q) = (2-q)\left(1 - \log_2(2-q)\right) + (1-q)\log_2(1-q)
I ( q ) = ( 2 − q ) ( 1 − log 2 ( 2 − q ) ) + ( 1 − q ) log 2 ( 1 − q )
当 p ⩾ q p \geqslant q p ⩾ q a = q a = q a = q
此时:
I ( q , p ) = I q ( p , q ) = q log q − p log p − ( 1 + q − p ) log ( 1 + q − p ) I(q, p) = I_q(p, q) = q\log q - p\log p -(1+q-p)\log(1+q-p)
I ( q , p ) = I q ( p , q ) = q log q − p log p − ( 1 + q − p ) log ( 1 + q − p )
即得:
d I d p = log ( 1 + q − p p ) = 0 \frac{dI}{dp} = \log \left( \frac{1+q-p}{p} \right) = 0
d p d I = log ( p 1 + q − p ) = 0
即:
p ( a = q ) ∗ = 1 + q 2 p^*_{(a = q)} = \frac{1 + q}{2}
p ( a = q ) ∗ = 2 1 + q
此时的互信息为:
I ( q ) = ( q + 1 ) ( 1 − log ( 1 + q ) ) + q log q I(q)=(q+1)(1-\log(1+q))+q\log q
I ( q ) = ( q + 1 ) ( 1 − log ( 1 + q ) ) + q log q
即:
C ( q ) ∈ { ( q + 1 ) ( 1 − log ( 1 + q ) ) + q log q , ( 2 − q ) ( 1 − log 2 ( 2 − q ) ) + ( 1 − q ) log 2 ( 1 − q ) } C(q)\in\left\{ (q+1)(1-\log(1+q))+q\log q, (2-q)\left(1 - \log_2(2-q)\right) + (1-q)\log_2(1-q) \right\}
C ( q ) ∈ { ( q + 1 ) ( 1 − log ( 1 + q ) ) + q log q , ( 2 − q ) ( 1 − log 2 ( 2 − q ) ) + ( 1 − q ) log 2 ( 1 − q ) }
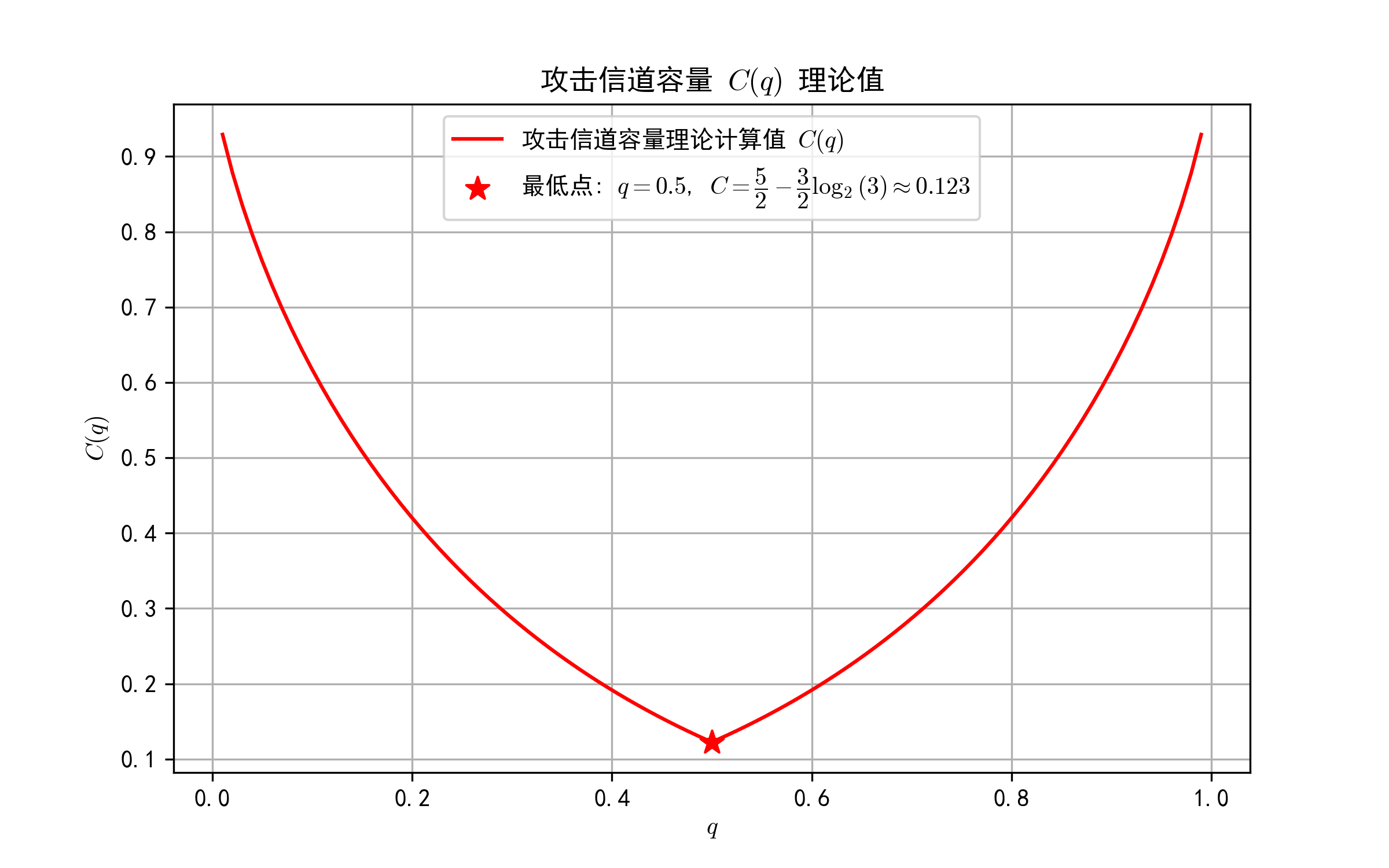
攻击信道容量
最终,我们就得到了下述关系式:
C ( q ) = { ( 1 + q ) ( 1 − log 2 ( 1 + q ) ) + q log 2 q , 0 < q ⩽ 1 2 ( 2 − q ) ( 1 − log 2 ( 2 − q ) ) + ( 1 − q ) log 2 ( 1 − q ) , 1 2 < q < 1 C(q) =
\begin{cases}
(1+q)\left(1 - \log_2(1+q)\right) + q\log_2 q, & 0 < q \leqslant \dfrac{1}{2} \\
(2-q)\left(1 - \log_2(2-q)\right) + (1-q)\log_2(1-q), & \dfrac{1}{2} < q < 1
\end{cases}
C ( q ) = ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ ( 1 + q ) ( 1 − log 2 ( 1 + q ) ) + q log 2 q , ( 2 − q ) ( 1 − log 2 ( 2 − q ) ) + ( 1 − q ) log 2 ( 1 − q ) , 0 < q ⩽ 2 1 2 1 < q < 1
攻击信道容量的意义为:黑客在单次攻击中所产生的针对红客的最大有效威胁当量 。展开来说就是在红客防守水平 q q q p p p a a a
理解 p p p q q q
q = 0 q = 0 q = 0 无防守无响应状态 )这时候黑客完全不需要探测或者获取情报(a = 0 a = 0 a = 0 如果黑客视角下攻击的成功概率(黑客盲自评)恰好为 p = 1 2 p = \frac{1}{2} p = 2 1 ,那么就算防守方后续真的去审计日志,也基本上完全辨别不出来,防守方完全不知道黑客来过,此时黑客产生的威胁达到最大 。q = 1 2 q = \frac{1}{2} q = 2 1 1 2 \frac{1}{2} 2 1 因为防守方自主筛掉了黑客一半的访问(不管是否合法)。 q = 1 q = 1 q = 1 大厦的可用性基本完全丧失 ,所有的资源都耗费在了防守上,大厦丧失了大厦最根本的服务功能。大概就是自己太内耗了反而黑客稍微煽动一下就破防了。
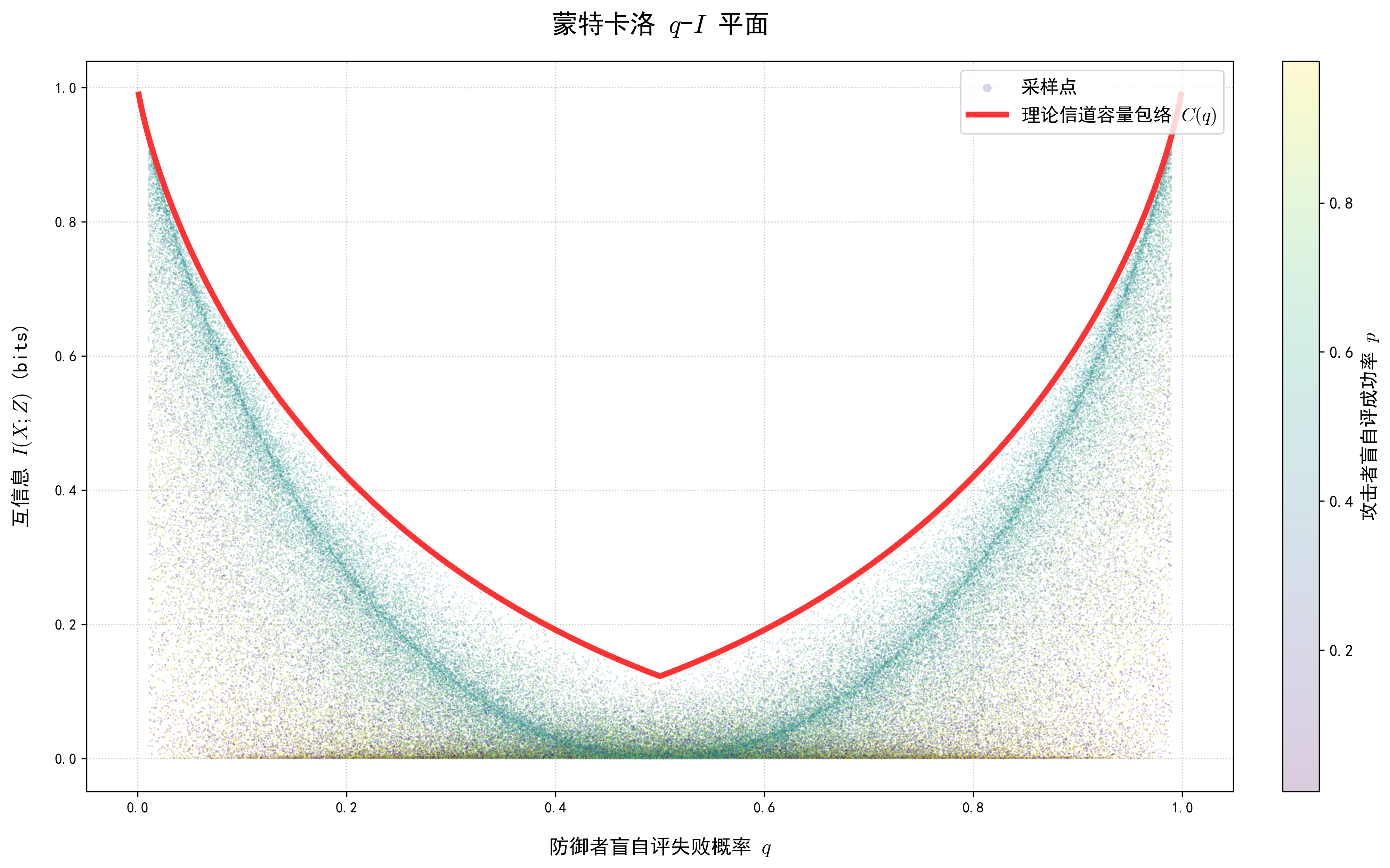
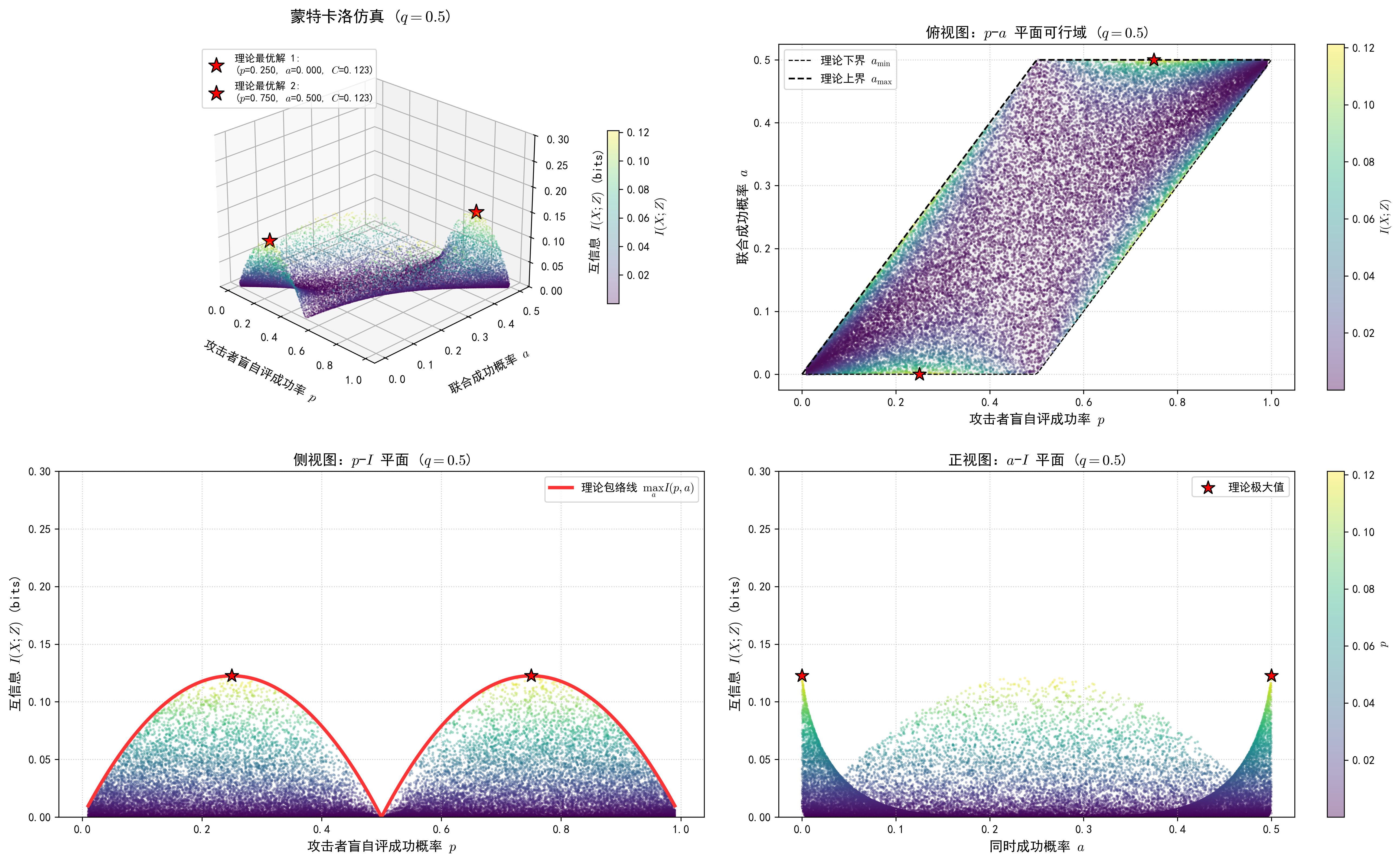
A.3 最后是一些蒙特卡洛模拟
对 q , p , a q, p, a q , p , a 这充分验证了我们前面对于闭式解计算的正确性。 但是这里有一个奇怪的现象,我们发现某一些点聚集在了另一条更低的曲线上(极值奇异性 ),这恰好是 a = p ⋅ q a = p\cdot q a = p ⋅ q 1 − H ( q ) 1 - H(q) 1 − H ( q ) 这种假设(盲自评相互独立)合理吗? 笔者认为是存在不同情况的,对点打击的黑客往往是对防守方的布防进行深入研究的,而像蠕虫这种暴力病毒在0day状态下确实可以考虑盲自评与防守方无关。
我们列出如下四组关系式:
在 0 ⩽ q < 1 2 0 \leqslant q < \frac{1}{2} 0 ⩽ q < 2 1 ( 1 + q ) ( 1 − log 2 ( 1 + q ) ) + q log 2 q (1+q)\left(1 - \log_2(1+q)\right) + q\log_2 q ( 1 + q ) ( 1 − log 2 ( 1 + q ) ) + q log 2 q a = 0 a = 0 a = 0 q q q
当 a = 0 a = 0 a = 0 p ∗ = 1 − q 2 p^* = \frac{1 - q}{2} p ∗ = 2 1 − q a ∗ = 0 a^* = 0 a ∗ = 0 a ∗ = 0 a^* = 0 a ∗ = 0 1 4 < p ⩽ 1 2 \frac{1}{4} < p \leqslant \frac{1}{2} 4 1 < p ⩽ 2 1
当 a = q a = q a = q p ∗ = 1 + q 2 p^* = \frac{1 + q}{2} p ∗ = 2 1 + q a ∗ = q a^* = q a ∗ = q a ∗ = 2 p − 1 a^* = 2p - 1 a ∗ = 2 p − 1 1 2 ⩽ p ⩽ 3 4 \frac{1}{2} \leqslant p \leqslant \frac{3}{4} 2 1 ⩽ p ⩽ 4 3
在 1 2 ⩽ q < 1 \frac{1}{2} \leqslant q < 1 2 1 ⩽ q < 1 ( 2 − q ) ( 1 − log 2 ( 2 − q ) ) + ( 1 − q ) log 2 ( 1 − q ) (2-q)\left(1 - \log_2(2-q)\right) + (1-q)\log_2(1-q) ( 2 − q ) ( 1 − log 2 ( 2 − q ) ) + ( 1 − q ) log 2 ( 1 − q ) a = p + q − 1 a = p + q - 1 a = p + q − 1 p p p
当 a = p + q − 1 a = p + q - 1 a = p + q − 1 p ∗ = 1 − q 2 p^* = 1 - \frac{q}{2} p ∗ = 1 − 2 q a ∗ = q 2 a^* = \frac{q}{2} a ∗ = 2 q a ∗ = 1 − p a^* = 1 - p a ∗ = 1 − p 1 2 < p ⩽ 3 4 \frac{1}{2} < p \leqslant \frac{3}{4} 2 1 < p ⩽ 4 3
当 a = p a = p a = p p ∗ = q 2 p^* = \frac{q}{2} p ∗ = 2 q a ∗ = q 2 a^* = \frac{q}{2} a ∗ = 2 q a ∗ = p a^* = p a ∗ = p 1 4 ⩽ p ⩽ 1 2 \frac{1}{4} \leqslant p \leqslant \frac{1}{2} 4 1 ⩽ p ⩽ 2 1
此时,我们均匀随机选取 q , p , a q, p, a q , p , a
接下来是分别针对固定的 q = 0.3 , 0.5 , 0.7 q = 0.3, 0.5, 0.7 q = 0 . 3 , 0 . 5 , 0 . 7 p , a p, a p , a q q q
q = 0.3 q = 0.3 q = 0 . 3
q = 0.5 q = 0.5 q = 0 . 5
q = 0.7 q = 0.7 q = 0 . 7
A.4 与 IND-CPA 的联系
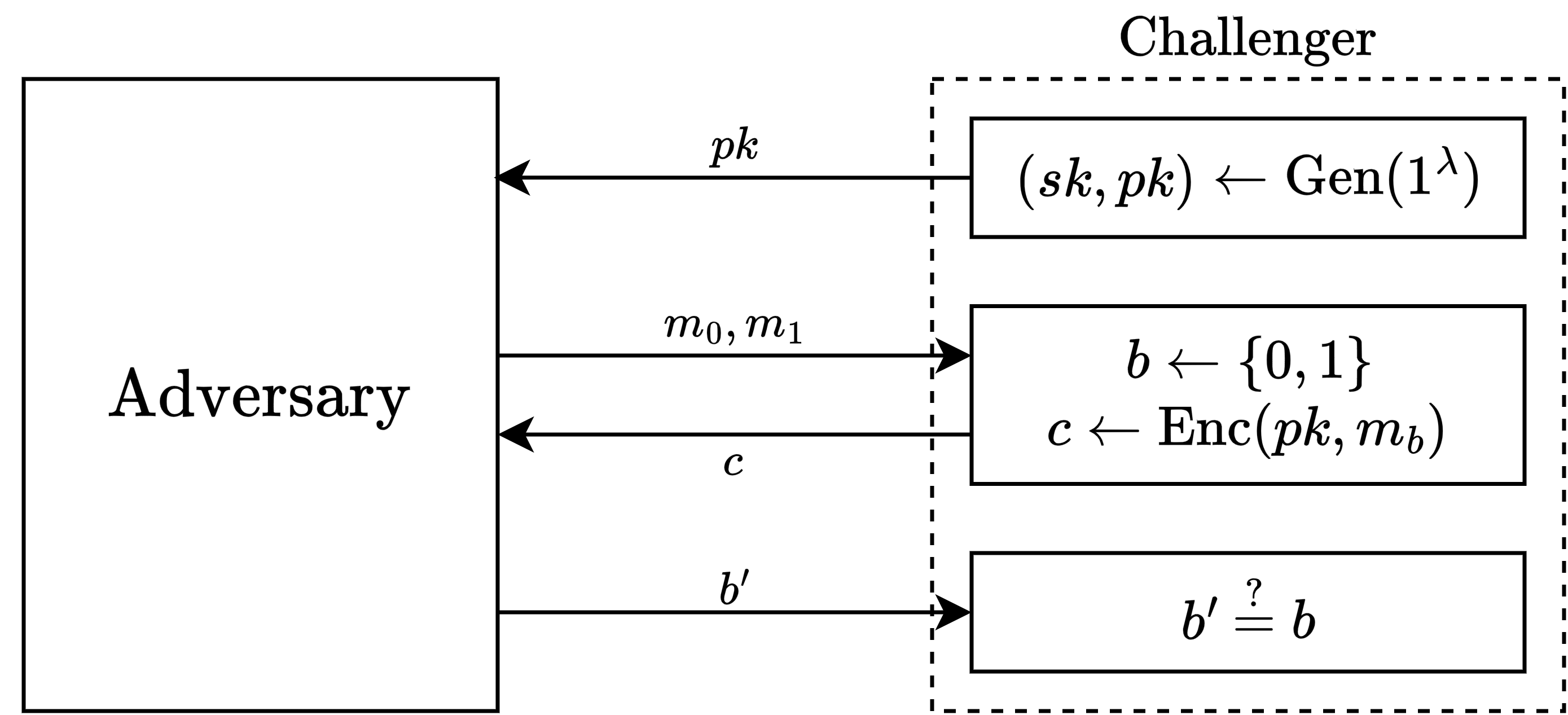
IND-CPA (选择明文攻击下的不可区分性)的具体定义为:
∀ \forall ∀ m 0 m_0 m 0 m 1 m_1 m 1 Enc ( p k , m 0 ) \text{Enc}(pk, m_0) Enc ( p k , m 0 ) Enc ( p k , m 1 ) \text{Enc}(pk, m_1) Enc ( p k , m 1 ) m 0 m_0 m 0 m 1 m_1 m 1 p k pk p k ∀ \forall ∀ A \mathcal{A} A
1 2 Adv IND ( A ) = ∣ Pr [ ( p k , s k ) ← Gen ( 1 λ ) , ( m 0 , m 1 ) ← A ( p k ) , b ← { 0 , 1 } , c ← Enc ( p k , m b ) , b ′ ← A ( p k , c ) : b ′ = b ] − 1 2 ∣ ⩽ negl ( λ ) \dfrac{1}{2}\text{Adv}_{\text{IND}}(\mathcal{A}) = \left|\Pr\left[\begin{aligned} &(pk, sk)\leftarrow \text{Gen}(1^{\lambda}), (m_0, m_1)\leftarrow\mathcal{A}(pk), b\leftarrow\{0, 1\},\\ &c\leftarrow\text{Enc}(pk, m_b), b'\leftarrow \mathcal{A}(pk, c):b'=b \end{aligned} \right] - \dfrac{1}{2}\right|\leqslant \text{negl}(\lambda)
2 1 Adv IND ( A ) = ∣ ∣ ∣ ∣ ∣ ∣ Pr [ ( p k , s k ) ← Gen ( 1 λ ) , ( m 0 , m 1 ) ← A ( p k ) , b ← { 0 , 1 } , c ← Enc ( p k , m b ) , b ′ ← A ( p k , c ) : b ′ = b ] − 2 1 ∣ ∣ ∣ ∣ ∣ ∣ ⩽ negl ( λ )
可以参考下图进行理解:
如果我们利用 IND-CPA (选择明文攻击下的不可区分性)构建信道,那么我们或许可以看到一些有趣的现象。
让我们观察一下 IND-CPA 安全模型中 Challenger(对应防守方) 和 Adversary(对应攻击方)之间的交互过程:
在密码学中,敌手 A \mathcal{A} A 它猜对的概率与随机猜测的偏差 :
Adv CPA ( A ) = ∣ Pr [ Z = X ] − 1 2 ∣ × 2 \text{Adv}_{\text{CPA}}(\mathcal{A}) = \left| \Pr[Z = X] - \frac{1}{2} \right| \times 2
Adv CPA ( A ) = ∣ ∣ ∣ ∣ ∣ Pr [ Z = X ] − 2 1 ∣ ∣ ∣ ∣ ∣ × 2
设 p 0 = Pr ( Z = 0 ∣ X = 0 ) p_0 = \Pr(Z=0\mid X = 0) p 0 = Pr ( Z = 0 ∣ X = 0 ) p 1 = Pr ( Z = 1 ∣ X = 1 ) p_1 = \Pr(Z=1\mid X=1) p 1 = Pr ( Z = 1 ∣ X = 1 ) A d v 0 = 2 p 0 − 1 \mathrm{Adv}_0 = 2p_0 - 1 A d v 0 = 2 p 0 − 1 A d v 1 = 2 p 1 − 1 \mathrm{Adv}_1 = 2p_1 - 1 A d v 1 = 2 p 1 − 1
A d v C P A = A d v 0 + A d v 1 2 \mathrm{Adv}_{\mathrm{CPA}} = \dfrac{\mathrm{Adv}_0 + \mathrm{Adv}_1}{2}
A d v C P A = 2 A d v 0 + A d v 1
为了便于计算,我们同时设 δ = A d v 0 − A d v C P A \delta = \mathrm{Adv}_0 - \mathrm{Adv}_{\mathrm{CPA}} δ = A d v 0 − A d v C P A A d v 1 = A d v C P A − δ \mathrm{Adv}_1 = \mathrm{Adv}_{\mathrm{CPA}} - \delta A d v 1 = A d v C P A − δ
首先计算 Pr ( Z = 0 ) \Pr(Z=0) Pr ( Z = 0 )
Pr ( Z = 0 ) = Pr ( X = 0 ) Pr ( Z = 0 ∣ X = 0 ) + Pr ( X = 1 ) Pr ( Z = 0 ∣ X = 1 ) \Pr(Z=0) = \Pr(X = 0)\Pr(Z=0\mid X=0) + \Pr(X = 1)\Pr(Z=0\mid X=1)
Pr ( Z = 0 ) = Pr ( X = 0 ) Pr ( Z = 0 ∣ X = 0 ) + Pr ( X = 1 ) Pr ( Z = 0 ∣ X = 1 )
Pr ( Z = 0 ) = 1 2 p 0 + 1 2 ( 1 − p 1 ) \Pr(Z=0) = \frac{1}{2}p_0 + \frac{1}{2}(1 - p_1)
Pr ( Z = 0 ) = 2 1 p 0 + 2 1 ( 1 − p 1 )
将 p 0 = 1 + A d v C P A + δ 2 p_0 = \dfrac{1 + \mathrm{Adv}_{\mathrm{CPA}} + \delta}{2} p 0 = 2 1 + A d v C P A + δ p 1 = 1 + A d v C P A − δ 2 p_1 = \dfrac{1 + \mathrm{Adv}_{\mathrm{CPA}} - \delta}{2} p 1 = 2 1 + A d v C P A − δ
Pr ( Z = 0 ) = 1 4 ( 1 + A d v C P A + δ ) + 1 4 ( 1 − A d v C P A + δ ) = 1 + δ 2 \Pr(Z=0) = \frac{1}{4}(1 + \mathrm{Adv}_{\mathrm{CPA}} + \delta) + \frac{1}{4}(1 - \mathrm{Adv}_{\mathrm{CPA}} + \delta) = \frac{1 + \delta}{2}
Pr ( Z = 0 ) = 4 1 ( 1 + A d v C P A + δ ) + 4 1 ( 1 − A d v C P A + δ ) = 2 1 + δ
同时:
H ( Z ∣ X ) = 1 2 H ( Z ∣ X = 0 ) + 1 2 H ( Z ∣ X = 1 ) = 1 2 H ( p 0 ) + 1 2 H ( p 1 ) H(Z\mid X) = \frac{1}{2}H(Z\mid X=0) + \frac{1}{2}H(Z\mid X=1) = \frac{1}{2}H(p_0) + \frac{1}{2}H(p_1)
H ( Z ∣ X ) = 2 1 H ( Z ∣ X = 0 ) + 2 1 H ( Z ∣ X = 1 ) = 2 1 H ( p 0 ) + 2 1 H ( p 1 )
在密码学中,由于敌手优势是可忽略的(即 A d v C P A , δ → 0 \mathrm{Adv}_{\mathrm{CPA}}, \delta \to 0 A d v C P A , δ → 0 ,我们可以利用二元熵函数在 p = 1 2 p=\frac{1}{2} p = 2 1 H ( 1 + x 2 ) ≈ 1 − x 2 2 ln 2 H\left(\frac{1+x}{2}\right) \approx 1 - \frac{x^2}{2\ln 2} H ( 2 1 + x ) ≈ 1 − 2 l n 2 x 2
I ( X ; Z ) = H ( 1 + δ 2 ) − 1 2 [ H ( 1 + A d v C P A + δ 2 ) + H ( 1 + A d v C P A − δ 2 ) ] ≈ ( 1 − δ 2 2 ln 2 ) − 1 2 [ ( 1 − ( A d v C P A + δ ) 2 2 ln 2 ) + ( 1 − ( A d v C P A − δ ) 2 2 ln 2 ) ] \begin{aligned}
I(X;Z) &= H\left(\frac{1 + \delta}{2}\right) - \frac{1}{2}\left[H\left(\frac{1 + \mathrm{Adv}_{\mathrm{CPA}} + \delta}{2}\right) + H\left(\frac{1 + \mathrm{Adv}_{\mathrm{CPA}} - \delta}{2}\right)\right]\\
&\approx \left(1 - \frac{\delta^2}{2\ln 2}\right) - \frac{1}{2}\left[\left(1 - \frac{(\mathrm{Adv}_{\mathrm{CPA}} + \delta)^2}{2\ln 2}\right) + \left(1 - \frac{(\mathrm{Adv}_{\mathrm{CPA}} - \delta)^2}{2\ln 2}\right)\right]
\end{aligned}
I ( X ; Z ) = H ( 2 1 + δ ) − 2 1 [ H ( 2 1 + A d v C P A + δ ) + H ( 2 1 + A d v C P A − δ ) ] ≈ ( 1 − 2 ln 2 δ 2 ) − 2 1 [ ( 1 − 2 ln 2 ( A d v C P A + δ ) 2 ) + ( 1 − 2 ln 2 ( A d v C P A − δ ) 2 ) ]
此时 δ 2 \delta^2 δ 2
I ( X ; Z ) ≈ ( 1 − δ 2 2 ln 2 ) − ( 1 − A d v C P A 2 + δ 2 2 ln 2 ) = ( A d v C P A ) 2 2 ln 2 I(X;Z) \approx \left(1 - \frac{\delta^2}{2\ln 2}\right) - \left(1 - \frac{\mathrm{Adv}_{\mathrm{CPA}}^2 + \delta^2}{2\ln 2}\right) = \dfrac{\left(\mathrm{Adv}_{\mathrm{CPA}}\right)^2}{2\ln 2}
I ( X ; Z ) ≈ ( 1 − 2 ln 2 δ 2 ) − ( 1 − 2 ln 2 A d v C P A 2 + δ 2 ) = 2 ln 2 ( A d v C P A ) 2
通过上式我们得到一个有趣的客观结论:基于密码学的攻击信道容量 C C C Adv CPA \text{Adv}_{\text{CPA}} Adv CPA C C C Adv 2 \text{Adv}^2 Adv 2
更有趣的是,接下来我们设:
A d v D = ∣ q − 1 2 ∣ \mathrm{Adv}_{\mathrm{D}} = \left|q - \frac{1}{2}\right|
A d v D = ∣ ∣ ∣ ∣ ∣ q − 2 1 ∣ ∣ ∣ ∣ ∣
我们发现攻击信道容量可以写成一个统一的表达式:
C ( A d v D ) = ( 3 2 − A d v D ) ( 1 − log 2 ( 3 2 − A d v D ) ) + ( 1 2 − A d v D ) log 2 ( 1 2 − A d v D ) C(\mathrm{Adv}_\mathrm{D}) = \left(\frac{3}{2} - \mathrm{Adv}_\mathrm{D}\right)\left(1 - \log_2\left(\frac{3}{2} - \mathrm{Adv}_\mathrm{D}\right)\right) + \left(\frac{1}{2} - \mathrm{Adv}_\mathrm{D}\right)\log_2\left(\frac{1}{2} - \mathrm{Adv}_\mathrm{D}\right)
C ( A d v D ) = ( 2 3 − A d v D ) ( 1 − log 2 ( 2 3 − A d v D ) ) + ( 2 1 − A d v D ) log 2 ( 2 1 − A d v D )
防守的“漏报”和“误报”在信息论视角下是等价的,它们都是确定性的泄露,都会被黑客利用,从而影响防守方的机密性,可用性,资源损耗等等。
如果我们对这个统一公式求 A d v D \mathrm{Adv}_\mathrm{D} A d v D
d C d A d v D = − 1 + log 2 ( 3 2 − A d v D 1 2 − A d v D ) \frac{dC}{d\mathrm{Adv}_\mathrm{D}} = -1 + \log_2\left(\frac{\frac{3}{2} - \mathrm{Adv}_\mathrm{D}}{\frac{1}{2} - \mathrm{Adv}_\mathrm{D}}\right)
d A d v D d C = − 1 + log 2 ( 2 1 − A d v D 2 3 − A d v D )
当 A d v D → 0 \mathrm{Adv}_\mathrm{D} \to 0 A d v D → 0 q → 1 2 q \to \frac{1}{2} q → 2 1
d C d A d v D ∣ A d v D = 0 = log 2 3 − 1 \left. \frac{dC}{d\mathrm{Adv}_\mathrm{D}} \right|_{\mathrm{Adv}_\mathrm{D}=0} = \log_2 3 - 1
d A d v D d C ∣ ∣ ∣ ∣ ∣ A d v D = 0 = log 2 3 − 1
这意味着在 q = 1 2 q=\frac{1}{2} q = 2 1 q = 1 2 q=\frac{1}{2} q = 2 1
A.5 对于攻击信道建模的总结
无论如何,防守方的响应状态越确定,黑客可能产生的最大威胁当量 越大,一定的威胁当量可能不会对系统直接造成破坏(不会直接破防),但是会对防守方的资源等造成损耗,防守方存在沉默成本。 而值得一提的是,实际而言,防守方构建完全 1 / 2 1/2 1 / 2
攻击信道容量存在非零正尖点,说明尖点附近黑客需要考虑突变式战术相变,且黑客的威胁永远存在。也就是说,在这个模型下,我们证明了绝对的安全是不存在的。
一拳超人总有他应顾不暇的时候,而谜语人对对方造成的迷惑最大。可惜这个时候防守方的可用性却被摧毁了。 总的来说还是,这个模型的计算完全可以脱离“安全”这个概念而存在 ,所以笔者理解这就是一个套皮解释的工作。这里的互信息或者信道容量我们完全可以直接理解成能量,即这里所说的(最大)威胁当量。当量大不代表防守方真的攻破了。先随着防守方盲自评增加,但是还没达到一半的时候,黑客的优势在于找到防守方没有防住的部分;当防守方的盲自评进一步增加,超过一半之后,对于黑客来说,客观上他要造成更大的威胁就是直接去硬碰硬防守方防住的地方。中间的尖点就是因为黑客的策略在 1 / 2 1/2 1 / 2